
با سلام
در محیط multitenant ، اگر تمایل دارید که پس از start شدن دیتابیس cdb ، دیتابیس های pdb تیز بصورت اتوماتیک open شوند، می توانید از trigger زیر استفاده کنید:
CREATE OR REPLACE TRIGGER open_pdbs AFTER STARTUP ON DATABASE BEGIN EXECUTE IMMEDIATE 'ALTER PLUGGABLE DATABASE ALL OPEN'; END open_pdbs; /
همچنین می توانیم بجای اینکه تمامی pdb ها open شوند، بخشی از آنها که مدنظر ماست را open کنیم. برای اینکار کافی است بجای all نام آنها را برده و با کاما "،" آنها را جدا کنیم.
----------------------------------------------------------------------------------------------------------------------------
لطفاً در هنگام رانندگی به احترام عابرین پیاده بایستیم.
سلام. اگر پارامتر STANDBY_FILE_MANAGEMENT در استندبای برابر manual باشد، زمانی که بخواهیم در دیتابیس اصلی دیتافایلی را اضافه کنیم، این کار بصورت اتوماتیک در استندبای رخ نمی دهد و باعث از کار افتادن استندبای تا حل این موضوع خواهد شد.
File #7 added to control file as 'UNNAMED00007' because
the parameter STANDBY_FILE_MANAGEMENT is set to MANUAL
The file should be manually created to continue.
Errors with log +FRA/testdg/archivelog/2018_09_04/thread_2_seq_155.574.985946453
MRP0: Background Media Recovery terminated with error 1274
Errors in file /u01/app/oracle/diag/rdbms/testdg/testdg2/trace/testdg2_mrp0_13384.trc:
ORA-01274: cannot add datafile '+DATA/testdb/datafile/audit_tbs.275.985944109' - file could not be created
alter database create datafile 7 as '+data';
Database altered.
سلام. Sql loader یکی از ابزارهایی هست که سرعت بسیار بالایی در ورود اطلاعات به دیتابیس داره. بعضی اوقات فکر می کنم که بخشی از اطلاعات را از حفظ می زنه :| .
فایل تستی که امروز می خوایم وارد کنیم بصورت زیر هست:
DATE,NUMBER_TEST,PHONE,TEXT_TEST
2018/08/23-11:10:17,121,78903456789,1_row
2018/08/24-11:11:17,131,78903256789,2_row
2018/08/22-11:12:17,141,78903456789,3_row
2018/08/27-11:13:17,151,78903456789,4_row
2018/08/24-11:14:17,161,78903456789,5_row
2018/08/29-11:15:17,171,78903456789,6_row
2018/08/21-11:20:17,181,78903456789,7_row
2018/08/24-11:30:17,191,78903356789,8_row
2018/08/20-11:40:17,101,78903436789,9_row
2018/08/24-11:50:17,111,78903456789,10_row
2018/08/22-12:10:17,121,78903456789,11_row
2018/08/21-13:10:17,131,78903456789,12_row
2018/08/13-14:10:17,141,78903453339,13_row
2018/08/14-15:10:17,161,78903456739,14_row
2018/08/25-15:11:17,171,78903456389,15_row
2018/08/29-12:10:17,181,78903453789,16_row
2018/08/21-11:10:27,191,78903456789,17_row
[oracle@db11g-node2 ~]$ cat sqlldr.ctl
OPTIONS (
SKIP=1,
PARALLEL=true,
DIRECT=true,
SKIP_INDEX_MAINTENANCE=true
)
LOAD DATA
APPEND
INTO TABLE VAHID_TEST_SQLLDR
FIELDS TERMINATED BY ","
TRAILING NULLCOLS
(
ID sequence,
DATE date 'yyyy/mm/dd,hh24:mi:ss',
NUMBER_TEST,
PHONE,
TEXT_TEST,
TEXT_CONSTANT constant 'vahidnowrouzi.blog.ir'
)
CREATE TABLE VAHID_TEST_SQLLDR
( "ID" NUMBER(20,0),
"DATE" DATE,
"NUMBER_TEST" NUMBER(3,0),
"PHONE" VARCHAR2(20 BYTE),
"TEXT_TEST" VARCHAR2(50),
"TEXT_CONSTANT" VARCHAR2(50)
);
sqlldr vahid/vahid data=/home/oracle/sqlldr.data control=/home/oracle/sqlldr.ctl log=/home/oracle/sqlldr.log bad=/home/oracle/sqlldr.bad
سلام. برای همه ما پیش اومده که مثلاً بخواهیم backup ی که گرفتیم رو با دستور scp به سرور دیگه ای انتقال بدیم. در این حین به علت قطع شدن session ممکنه تو حجم بالا، عملیات انتقال با مشکل مواجه بشه. برای این کار می توان از ارسال این دستور به background به روش زیر استفاده کرد:
nohup scp file_to_copy user@server:/path/to/copy/the/file > nohup.out 2>&1
پس از این مرحله پسورد رو وارد می کنیم و بعد ctrl+z را می زنیم. حالا دستور را با دستور bg به background می فرستیم. برای اینکه اون رو به foreground برگردونیم، می تونیم با زدن دستور jobs لیست کارهای background را ببنیم و با زدن شماره اون job روبروی دستور fg اون رو ببنیم.
منبع: http://charmyin.github.io/scp/2014/10/07/run-scp-in-background/
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
لطفاً در هنگام رانندگی به احترام عابرین پیاده بایستیم.
سلام. چند روز پیش توی لاگهای دیتابیس یکی از مشتری ها، DEADLOCK دیدم و بهشون گفتم که مشکل رو حل کنید. بعد که بیشتر دقت کردم، دیدم که enq: TX - allocate ITL entry داره که زیر مجموعه CONFIGURATION حساب میشه. برای پیدا کردن ربط اون به deadlock باید چند تا مطلب رو مرور کنیم.
مطلب اول. ITL:
در اوراکل زمانی که برای یک سطر lock توسط یک transaction رخ می دهد، اطلاعات مربوط به آن در header آن block ی قرار می گیرد که داده در آن است. حال زمانی که transaction دیگری می خواهد با همان row کار کند، باید باز هم به سراغ همان block header برود و با اطلاعاتی که در حال حاضر در این قسمت موجود است ، متوجه lock بودن آن سطر می شود. بنابراین به پروسسی که در تئوری به عنوان lock manager ممکن است درست کار کند، دیگر نیازی نیست. به این ساختار داده ای ، Interested Transaction List یا به اختصار ITL گفته می شود که در آن اطلاعات transaction و rowid نگه داری می شود. هر ITL چندین slot برای transactionها دارد. زمانی که transactionِ ی برای اولین بار به سراغ block می آید، شماره rowid در یکی از slotها قرار می گیرد. همینطور زمانی که همین transaction و یا transaction دیگری بخواهد با سطرهای این block کار کند، در slot بعدی قرار می گیرد.
مطلب دوم، initrans:
در زمان ساخت جدول، این پارامتر مشخص می کند که در ابتدا چند slot در ITL وجود داشته باشد.
مطلب سوم، maxtrans:
زمانی که transaction جدیدی برای lock کردن سطری در همین block می آید، slot جدیدی در ITL تشکیل می شود و این تعداد تا MAXTRANS می تواند ادامه یابد.
مطلب چهارم، pctfree:
میزان درصدی که اوراکل برای هر بلاک برای update های بعدی در یک بلاک خالی می گذارد، یعنی اگر pctfree برابر 10 باشد، داده ها تا 90 درصد بلاک را پر خواهند کرد و تنها 10 درصد را برای update های بعد خالی می گذارند.
حالا ببنیم که ITL WAIT چطور پیش میاد. زمانی که در یک block نمی توان slot جدید ایجاد شود، transaction تازه ورود باید منتظر خالی شدن slot های قبلی بشود و بنابراین wait پیش می آید. یک بلاک بلافاصله بعد از بوجود آمدن به شکل زیر است:

چون initrans در ابتدا بصورت پیشفرض یک است ، بنابراین تنها یک slot در ITL وجود دارد. حالا فرض کنیم تعداد INSERT در این بلاک انجام می شود.

حالا transaction اول row1 را update می کند ولی commit نمی کند و بنابراین slot مربوط به آن باقی می ماند،

trnsaction بعدی row2 را update می کند و باز هنوز commit نکرده است. نتیجه می شود:

نتیجه این می شود که با اینکه در مثال ما maxtrans را برابر 11 در نظر گرفته ایم، جایی برای itl slot جدید نخواهد بود.
حالا به سراغ deadlock می رویم که بر اساس داکیومنت شماره 2266279.1 دلیل آن این است که transaction 1 یک ITL بر روی بلاک A دارد و یک تقاضا برای گرفتن ITL بر روی بلاک B و در همین زمان transaction 2 یک ITL بر روی بلاک B دارد و نقاضا برای گرفتن بلاک A که نتیجه deadlock می شود.
راه حل:
افزایش initrans و pctfree در جداول و ایندکسهایی که در این deadlock در گیر هستند. پیشنهاد اوراکل initrans=30 و pctfree=30% است. پس از این تغییرات باید جدول و ایندکسها را move و rebuild کرد.
نکته: دقت داشته باشید که در صورتی که بخواهید این جدول را move کنید، جدول lock خواهد شد و همچنین در زمان rebuild تعدادی متناسب با حجم ایندکس، archive log تولید می گردد. بنابراین زمان و حجم مناسب برای اینکار را انتخاب کنید.
منابع:
http://www.proligence.com/itl_waits_demystified.html
ORA-60 Deadlock 'ENQ: TX - ALLOCATE ITL ENTRY' Error - Doc ID 2266279.1
http://www.orafaq.com/wiki/PCTFREE
----------------------------------------------------------------------------------------------------------------------------------------
لطفاً در هنگام رانندگی به احترام عابرین پیاده بایستیم.
سلام
یکی از کارهایی که باید چندین بار در محیط تست انجام داد و براش آماده بود، Switchover هست. هر دیتابیس می تواند یکی از دو role شامل primary و یا standby را داشته باشد. عملیات switchover به ما اجازه می دهد بدون از دست دادن داده و یا reset log نقش این دو دیتابیس را عوض کنیم.
عملیات switchover کاربردهای زیادی دارد که از آن جمله می توان به downtime از پیش تعیین شده برای نگه داری، تعمیر سخت افزار، جابجایی فیزیکی سرورها و اشاره کرد.
در این مطلب ما دو rac با نسخه 11.2.0.4 داریم. ابتدا بر روی هر کدام از دیتابیس ها، دستور زیر را برای به دست آوردن اطلاعات و نقش فعلی آنها می زنیم:
select name,open_mode,db_unique_name,switchover_status,database_role from v$database;
نتیجه دیتابیس اصلی به شکل زیر خواهد بود:
NAME OPEN_MODE DB_UNIQUE_NAME SWITCHOVER_STATUS DATABASE_ROLE
--------- -------------------- ------------------------------ -------------------- ----------------
TESTDB READ WRITE testdb TO STANDBY PRIMARY
NAME OPEN_MODE DB_UNIQUE_NAME SWITCHOVER_STATUS DATABASE_ROLE
--------- -------------------- ------------------------------ -------------------- ----------------
TESTDB MOUNTED TESTDG NOT ALLOWED PHYSICAL STANDBY
archive log list
select process ,sequence# , status , thread# from gv$managed_standby;
select thread#, max(sequence#) from v$archived_log where applied='YES' group by thread#;
alter database commit to switchover to physical standby;
alter database commit to switchover to physical standby with session shutdown ;
دیتابیس استندبای را یکبار خاموش و تا مرحله mount بالا می آوریم:
shut immediate;
startup mount;
حالا اگر جستجوی اول کار را بر روی دیتابیس اصلی جدید (استندبای قدیمی) اجرا کنیم، می بینیم که وضعیت switchover_status تغییر پیدا کرده است:
select name,open_mode,db_unique_name,switchover_status,database_role from v$database;
NAME OPEN_MODE DB_UNIQUE_NAME SWITCHOVER_STATUS DATABASE_ROLE
--------- -------------------- ------------------------------ -------------------- ----------------
TESTDB MOUNTED TESTDG TO PRIMARY PHYSICAL STANDBY
alter database commit to switchover to primary ;
shut immediate;
startup;
select name,open_mode,db_unique_name,switchover_status,database_role from v$database;
NAME OPEN_MODE DB_UNIQUE_NAME SWITCHOVER_STATUS DATABASE_ROLE
--------- -------------------- ------------------------------ -------------------- ----------------
TESTDB READ WRITE TESTDG RESOLVABLE GAP PRIMARY
recover managed standby database using current logfile disconnect;
سلام مجدد.
در قسمت قبل نصب grid به اتمام رسید. در این قسمت کار رو به اتمام می رسونیم.
اول باید فایلهای مربوطه به دیتابیس رو در مسیر دلخواهمون extract کنیم. من معمولاً یک date رو در انتهای دو دستور unzip می گذارم که از صحت عملکرد دو unzip قبل با این روش مطمئن بشم.

گزینه i wish را uncheck می کنیم.:
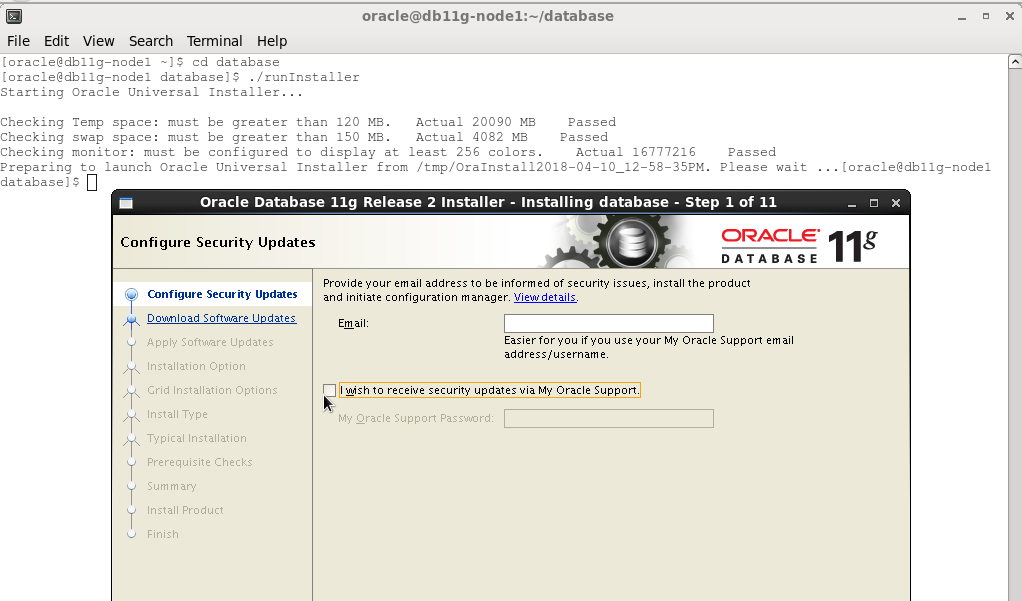
گزینه skip software update را انتخاب می کنیم.

در اینجا فقط نرم افزار دیتابیس را نصب می کنیم:

بر روی تمامی node ها نصب را انجام خواهیم داد پس node دوم را هم انتخاب می کنیم:

تنظیمات مربوط به ssh را وارد می کنیم و بر روی setup کلیک می کنیم.

زبان مورد نظر را وارد می کنیم

گزینه enterprise را انتخاب می کنیم:

مسیرهای مورد نظر را قبول می کنیم.

گروه های پیشنهاد شده را قبول می کنیم:
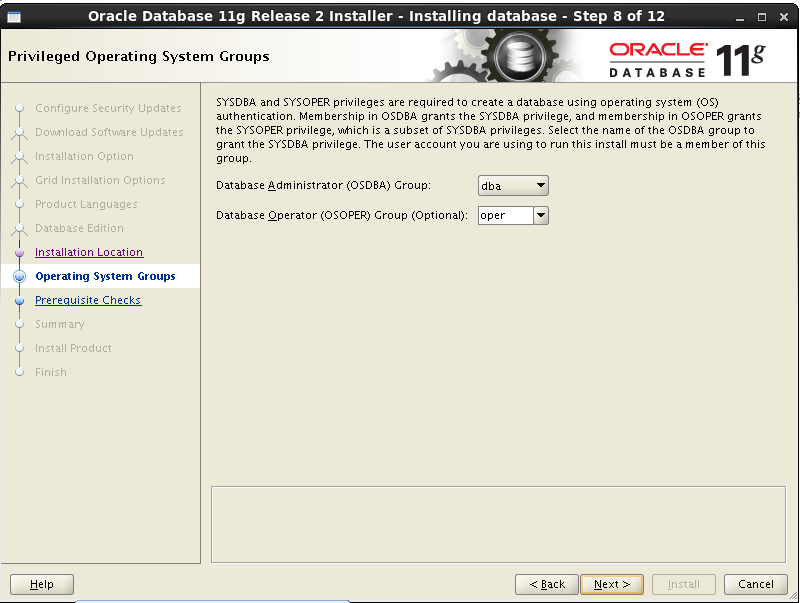
مشکل ntp را ignore می کنیم. بهتر این است که وقت بگذارید و این مشکل را مرتفع کنید.

دستور install را می زنیم:

اسکریپتهای مربوط به root را با کاربر root اجرا می کنیم:

پس از اتمام نصب برای ساخت دیسکهای دیگر Asm با کاربر grid وارد می شویم و تنظیمات مربوطه را در bash_profile. در مسیر home/grid/ وارد می کنیم:

با زدن دستور Asmca به محیط آن وارد می شویم. دیسک ocr را از قبل ساخته ایم:

بر روی Create کلیک کرده و با انتخاب redundancy از نوع external و انتخاب دیسک Data01 ، گروه data را می سازیم.

سپس گروه fra را نیز با همین روش می سازیم. نتیجه بصورت ذیل خواهد شد:

تحت کاربر اوراکل در مسیر home/oracle/ فایل bash_profile. را بصورت زیر ویرایش می کنیم:

دستور dbca را اجرا می کنیم.
نکته: برای اینکه تغییرات جدید در shell حاضر اعمال شود، باید دستور home/oracle/.bahs_profile/ . را اجرا کنیم.

گزینه create را انتخاب می کنیم.

گزینه general را انتخاب می کنیم:

تمامی node ها را انتخاب می کنیم و دیتابیس را نامگذاری می کنیم:

گزینه ها را بصورت پیش فرض قبول می کنیم:

پسورد مدنظر خود را انتخاب و وارد می کنیم:

در قسمت Storage type ما ASM را انتخاب می کنیم و دیسک گروه data را برای این کار قرار می دهیم.

برای recovery area دیسک گروه fra را انتخاب می کنیم. همچنین archive را enable می کنیم.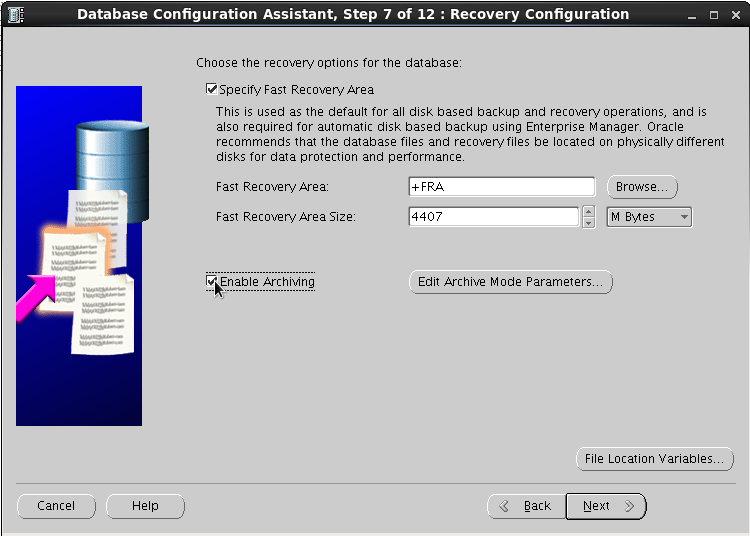
برای تستهای بعدی sample schema را فعال می کنیم:

character set را al32utf8 در تست ما قرار می دهیم. در محیط های واقعی درصورتی که بخواهیم دامپ از جایی بیاوریم، حتماً با صادر کننده دامپ در این زمینه هماهنگ باشیم.

بر روی next کلیک می کنیم

بر روی finish کلیک می کنیم:
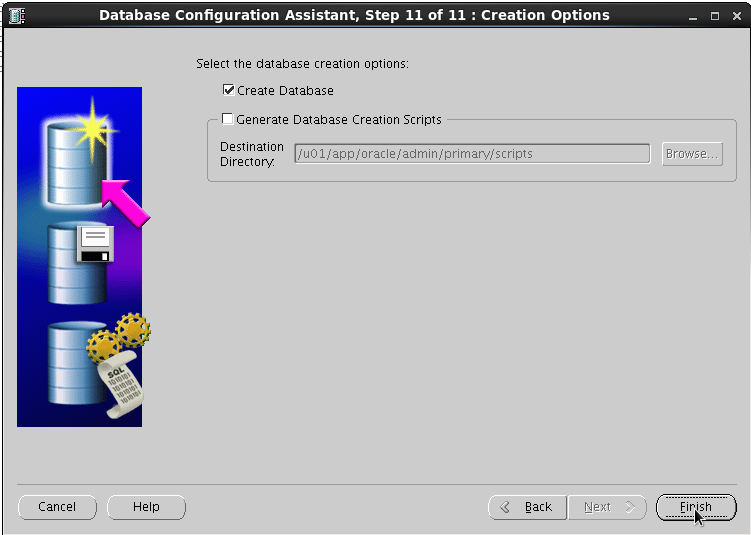
نصب به اتمام رسید. در صورتی که بخواهیم پسوردی را تغییر دهیم، می توانیم در این مرحله هم انجام دهیم.
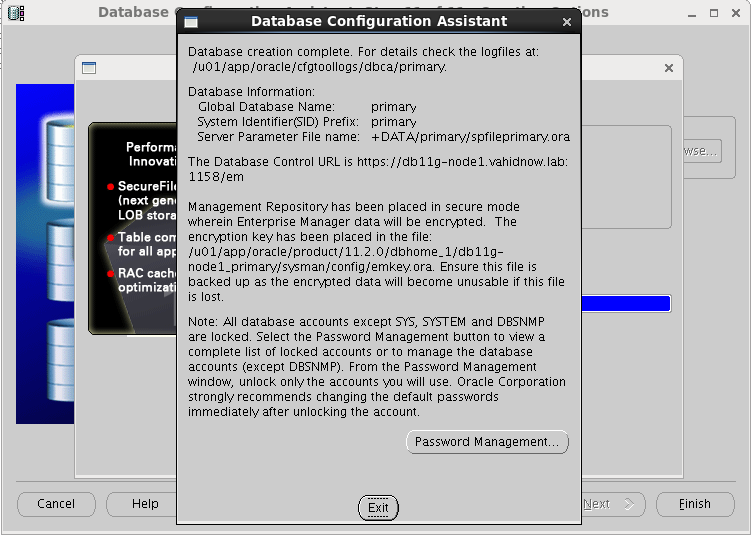
امیدوارم این مجموعه آموزش مفید واقع بشه.
----------------------------------------------------------------------------------------------------------------------
خواهشمند است در هنگام رانندگی به احترام عابرین پیاده بایستیم.
سلام. قسمت قبل preinstallation به اتمام رسید و حالا به سراغ نصب Grid می رویم.

دستور Date پس از دستور unzip برای اطمینان از صحت عملکرد unzip است . اگر نخواهید اینکار را انجام دهید می توانید از ?$ echo استفاده کنید. حالا گزینه skip را انتخاب می کنیم.

گزینه اول که مربوط به نصب کلاستر هست را انتخاب می کنیم.
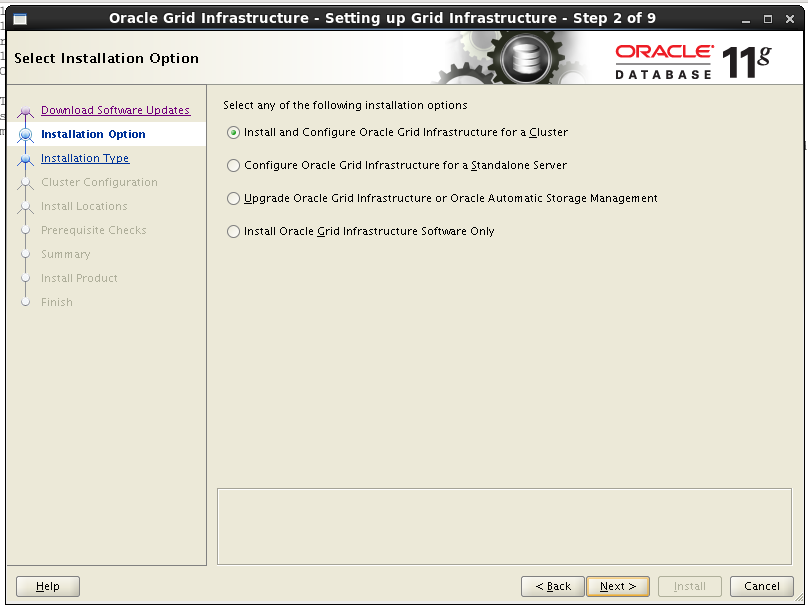
گزینه advanced را انتخاب می کنیم.
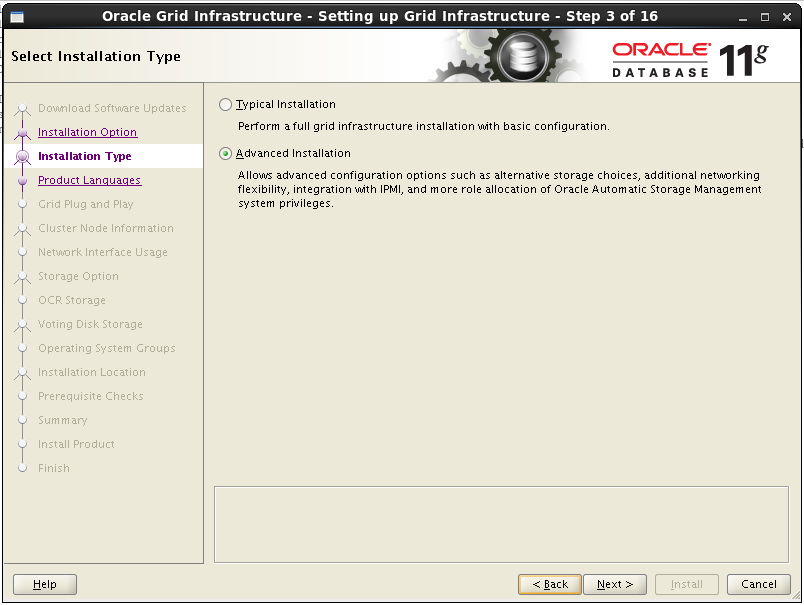
زبان انگلیسی را انتخاب می نمائیم.

نام کلاستر را انتخاب می نمائیم و نام scan را بر اساس نامی که در dns وارد نموده ایم وارد می نمائیم.

اطلاعات دومین node را با زدن کلید add اضافه می نمائیم .
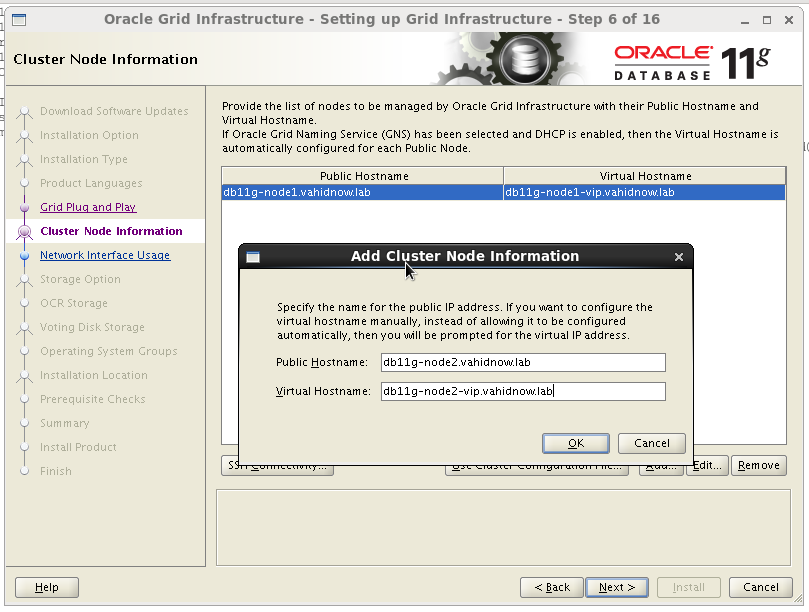
پس از زدن کلید ssh connectivity و وارد نمودن اطلاعات مورد نیاز، setup را می زنیم.

در صورتی که همه چیز درست باشد با پیغام زیر مواجه می شویم.

در صفحه بعد کارتهای شبکه متناسب را انتخاب می کنیم.

گزینه Asm را انتخاب می کنیم

با توجه به اینکه تنها یک دیسک را در نظر گرفته ایم برای هر گروه ، گزینه external را انتخاب کرده و نام دیسک را ocr می گذاریم و دیسک 2 گیگابایتی را به آن اختصاص می دهیم.

رمز عبور مدنظر خود را وارد کنید.
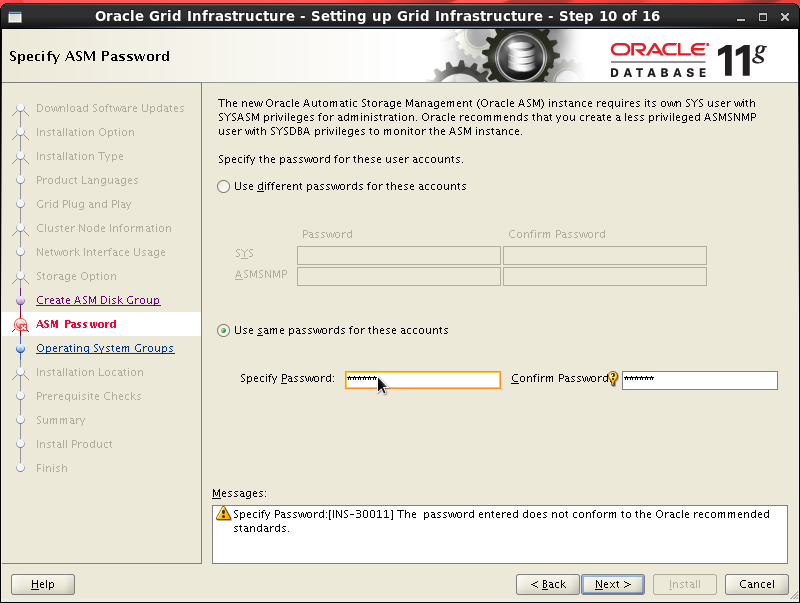
گزینه عدم استفاده از ipmi را انتخاب می کنیم.

با توجه به اینکه مراحل preinstallation را صحیح انجام داده ایم، گروه ها در جای درست خود قرار گرفته اند:

مسیرهای مناسب را می دهیم.
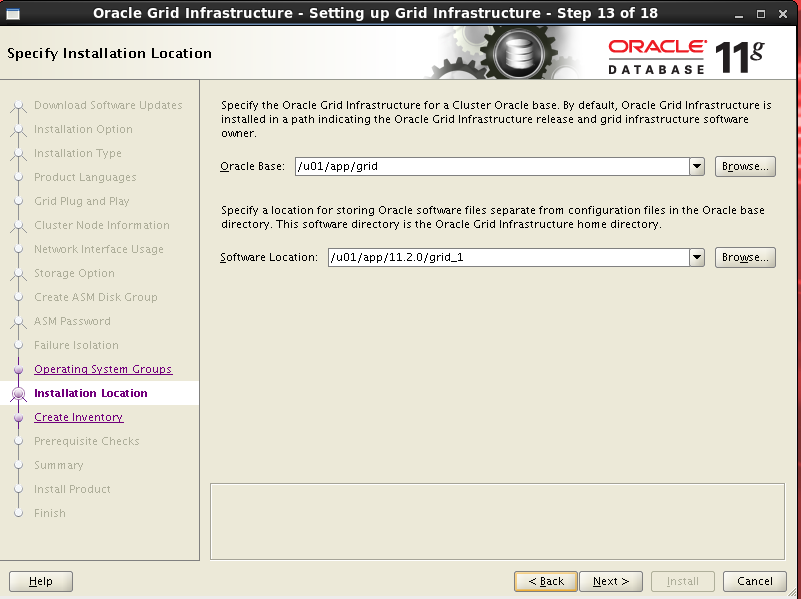
مسیر انتخاب شده را تایید می کنیم:

مراحل check انجام می شود و در صورتی که مشکلی وجود داشته باشد اطلاع داده می شود:

آنهایی که قابل رفع شدن توسط خود اوراکل هستند ، با زدن گزینه fix and check again و با اجرای اسکریپت توسط root بر طرف خواهند شد.

خطایی که درباره ntp به من داده بود رو با توجه به sync بودن crony ، نادیده گرفتم. اگر دوستان نظری دارند که می تونه این رو هم برطرف کنم، بگن که تصحیح کنم. اما به نظرم مشکلی برام ایجاد نخواهد کرد.

خلاصه ای از اطلاعات ارائه می شه در این مرحله:

اسکریپتهای نشان داده شده رو به ترتیب گفته شده بر روی node های یک و دو اجرا می کنیم.
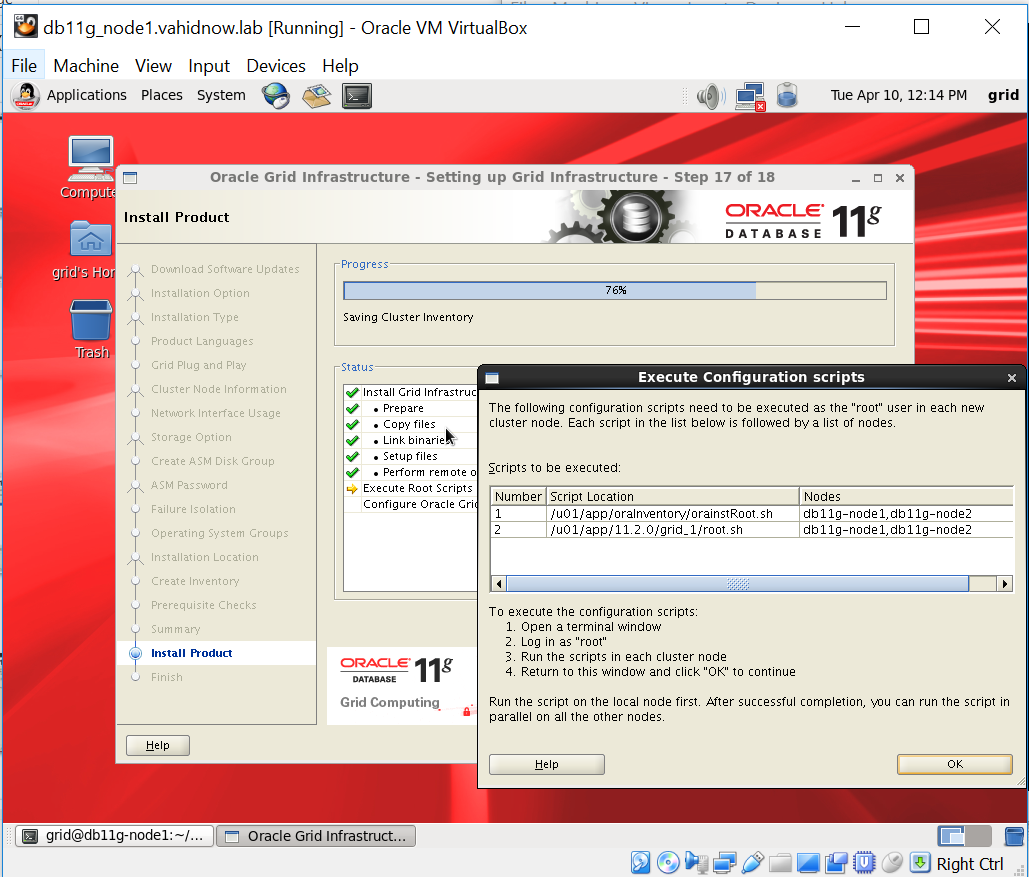
با توجه به اینکه ntp را ignore کرده بودیم ، با خطا در انتهای نصب مواجه می شویم که اگر لاگ رو بخونید ، می بینید که فقط در همین مورد هست و مشکل خاصی نداره.

نصب به اتمام رسید. در قسمت بعد به سراغ ساخت دیسک گروه های دیگر و نصب اوراکل می رویم.
-------------------------------------------------------------
لطفاً در هنگام رانندگی به احترام عابرین پیاده بایستیم.
سلام.
در قسمت قبل clone به اتمام رسید. حالا به سراغ ادامه کار می رویم.
ماشینهایی که برای اینکار در نظر گرفته ایم را روشن می کنیم. به سراغ فایل etc/sysconfig/network/ رفته و آنرا متناسب با فایل etc/hosts/ ویرایش می کنیم:

کارت شبکه ها رو باز هم بر طبق etc/hosts/ بصورت زیر بر روی هر یک از ماشینها کانفیگ می کنیم:

کارت شبکه Eth1 برای private در نظر گرفته ایم بصورت زیر کانفیگ می کنیم. در تصویر netmask=255.255.255.0 نیامده است که آنرا هم اضافه کنید.
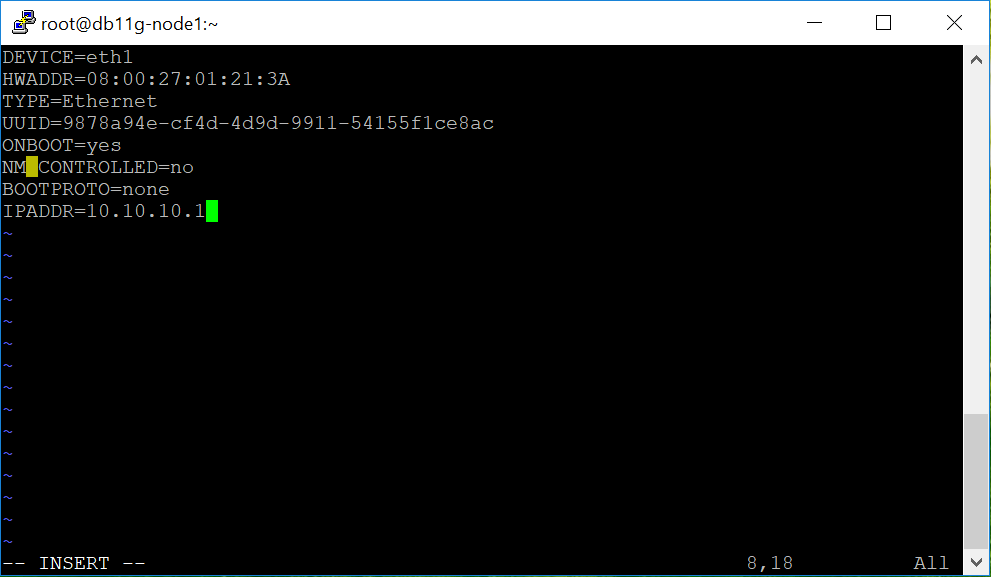
از روی اطلاعات موجود در etc/hosts/ باید کارتهای شبکه public و private را بتوان با نام ping کرد. این تست را انجام می دهیم.

ماشنیها را خاموش می کنیم. به قسمت Setting ماشین اول رفته و از قسمت storage و قسمت sata بر روی دکمه روبرویش برای اضافه کردن دیسک کلیک می کنیم و گزینه Create new disk را بر می گزینیم.

در قسمت زیر روی vdi کلیک می کنیم:

من در تستهایم گزینه fixed size را انتخاب کرده ام .

میزان حجم مورد نظر و همجنین نام و محل ساختن را انتخاب می کنیم. بهتر است برای خوانایی بیشتر پوشه مجزایی برای shared diskها در نظر گرفته شود. ocr را می سازیم با حجم 2 گیگابایت.

دیسکهای data و fra را نیز با حجم 10 گیگابایت به همین روش می سازیم. در انتهای ساخت دیسکها بصورت زیر خواهد شد:

از منوی اصلی vbox و از منوی فایل گزینه virutal media manager را اجرا می کنیم. در اینجا دیسکهایی که به منظور shared disk ساخته ایم را انتخاب کرده و type آنها را به shareable تغییر می دهیم:

حالا به Setting دومین node رفته و از قسمت storage بر روی گزینه روبروی کنترلر sata ، گزینه اضافه کردن دیسک را می زنیم و اینبار بجای انتخاب create disk گزینه choose existing disk را انتخاب و تک تک shared disk های ساخته شده را به آن می دهیم. نتیجه کار به شکل زیر خواهد بود.

حالا هر دو node را روشن می کنیم. اگر بر روی هر یک از دو node دستور lsblk را اجرا کنیم با تصویر زیر مواجه می شویم که نشان می دهد ، دیسکها به هر دوی آنها اضافه شده است:
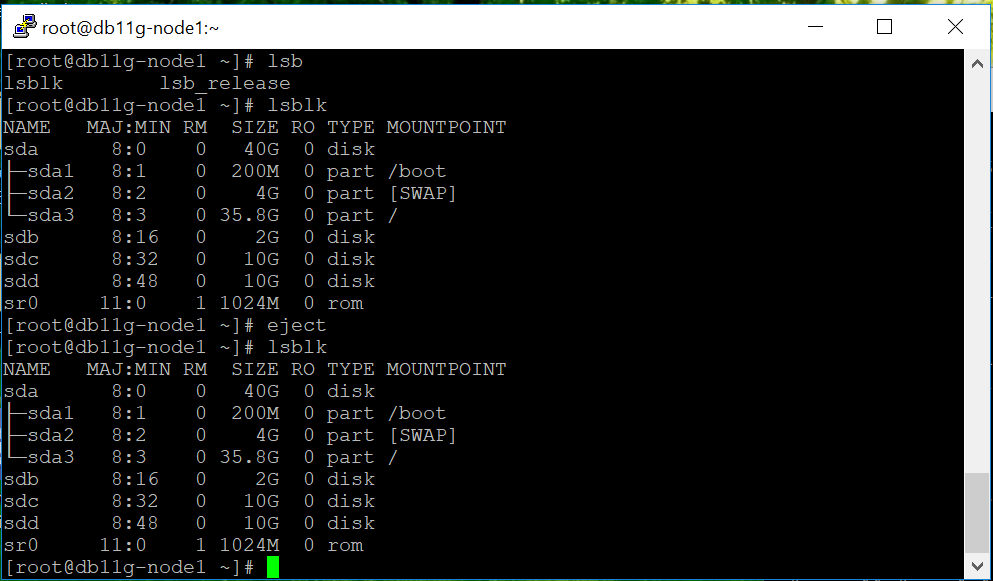
دیسکها را مطابق شکل زیر با دستور fdisk پارتیشن بندی می کنیم:

اینکار را برای تمامی دیسکهای جدید که شامل sdb , sdc , sdd می شود انجام می دهیم. بر روی node دیگر دستور partproble را می زنیم که تغییراتی که در node اول داده ایم دیده شود:

بر روی node اول ابتدا ownership دیسکها را درست کرده و دستور createdisk را مطابق شکل می زنیم. سپس بر روی node دوم تنها با زدن دستور oracleasm scandisks باید دیسکهای ساخته شده دیده شوند.
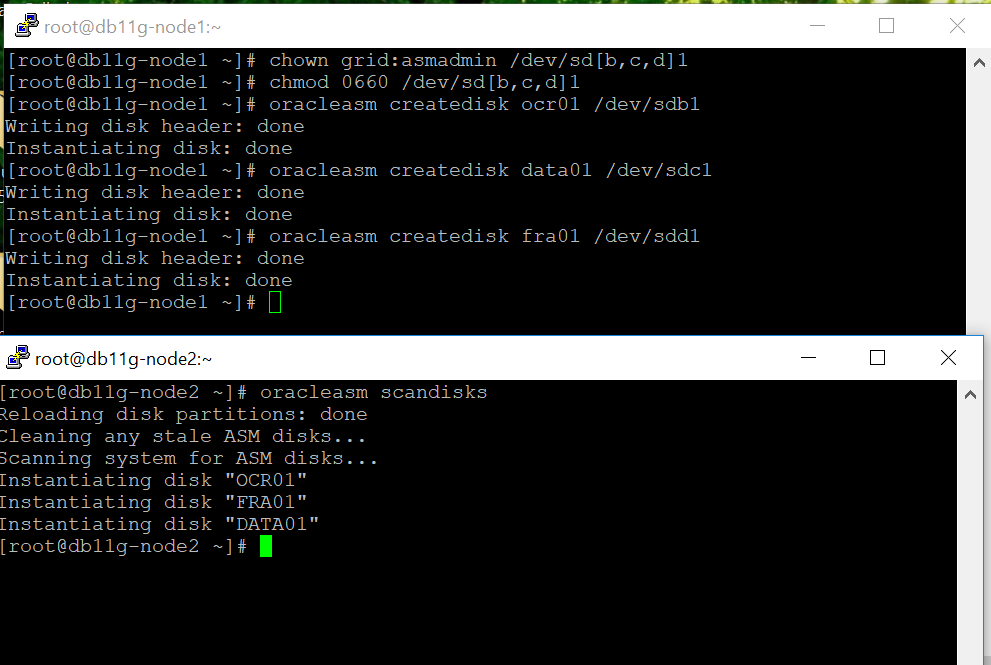
در قسمت بعد به سراغ نصب grid خواهیم رفت.
------------------------------------------------------------------------------------------------
لطفاً در هنگام رانندگی به احترام عابرین پیاده بایستیم.


درباره این سایت